When writing SQL queries, it is essential to understand the order in which SQL clauses are executed. This helps in writing optimized queries, especially when transitioning from SQL to PySpark. In this blog, we’ll walk you through the SQL execution order, the SQL clauses, and provide their corresponding PySpark syntax.
SQL Execution Order and Corresponding PySpark Syntax
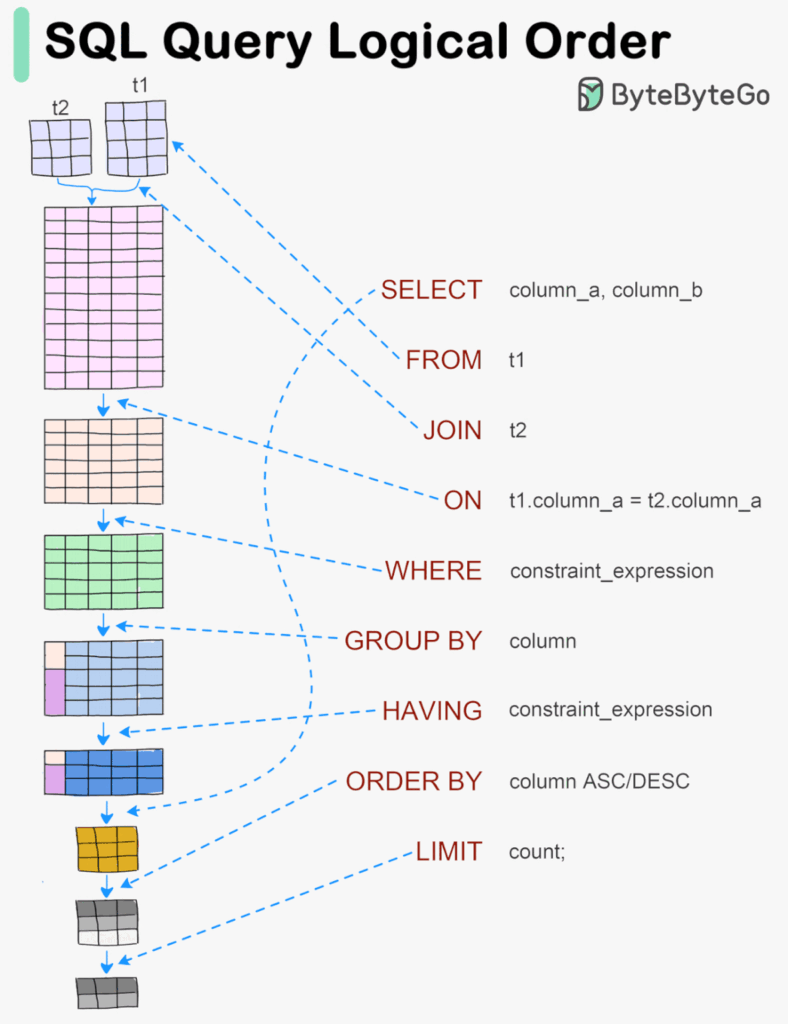
Below is a detailed table outlining the execution order for SQL clauses, a description of each step, and the corresponding PySpark syntax. This will act as a quick reference for anyone transitioning between SQL and PySpark for data processing.
SQL Clause Execution Order |
SQL Clause |
Description |
Spark (PySpark) Syntax |
|---|---|---|---|
1 |
FROM / JOIN |
Data is retrieved from the source tables and joins are performed if needed. |
df1.join(df2, df1.column == df2.column) |
2 |
ON |
Join condition, specifying how to match records from multiple tables. |
df1.join(df2, “column_name”) |
3 |
WHERE |
Filters rows based on the given conditions (before grouping or aggregation). |
df.filter(“column_name > value”) or df.filter(col(“column_name”) > value) |
4 |
GROUP BY |
Groups rows for aggregation. |
df.groupBy(“column_name”).agg(func.sum(“other_column”).alias(“sum_value”)) |
5 |
HAVING |
Filters groups based on conditions after aggregation. |
df.groupBy(“column_name”).agg(func.count(“*”).alias(“count”)).filter(“count > 5”) |
6 |
SELECT |
Specifies the columns to be included in the result set, as well as expressions. |
df.select(“column1”, “column2”) or df.select(col(“column1”), (col(“column2”) * 2).alias(“double_column”)) |
7 |
DISTINCT |
Removes duplicate rows after the SELECT operation. |
df.distinct() |
8 |
UNION / UNION ALL / INTERSECT / EXCEPT |
Combines results from multiple queries, returning the union, intersection, or difference. |
df1.union(df2) or df1.unionAll(df2) (Spark’s unionAll is equivalent to SQL’s UNION ALL) df1.intersect(df2) or df1.except(df2) |
9 |
ORDER BY |
Sorts the results based on specified column(s) in ascending or descending order. |
df.orderBy(“column_name”, ascending=True) or df.orderBy(col(“column_name”).desc()) |
10 |
LIMIT / OFFSET |
Restricts the number of rows returned (pagination or row limitation). |
df.limit(10) (for limiting rows) |
| Rest can vary | |||
11 |
WITH (CTE) |
Defines Common Table Expressions (CTEs), allowing the use of temporary result sets in the query. |
Spark doesn’t directly support CTEs, but you can create temporary views: df.createOrReplaceTempView(“view_name”) |
12 |
CASE / WHEN |
Provides conditional logic within the SELECT or WHERE clause. |
df.withColumn(“new_column”, when(col(“column_name”) > 100, “High”).otherwise(“Low”)) |
13 |
JOIN Types (INNER, LEFT, RIGHT, FULL) |
Specifies the type of join (inner, left outer, right outer, full outer). |
df1.join(df2, “column_name”, “left”) or df1.join(df2, “column_name”, “inner”) or df1.join(df2, “column_name”, “full”) or df1.join(df2, “column_name”, “right”) |
14 |
IN / NOT IN |
Filters data based on whether a value matches a set of values. |
df.filter(col(“column_name”).isin(value1, value2, value3)) or df.filter(~col(“column_name”).isin(value1, value2)) |
15 |
LIKE |
Used for pattern matching with strings. |
df.filter(col(“column_name”).rlike(“pattern”)) |
16 |
IS NULL / IS NOT NULL |
Checks for NULL values in columns. |
df.filter(col(“column_name”).isNull()) or df.filter(col(“column_name”).isNotNull()) |
17 |
ROLLUP / CUBE / GROUPING SETS |
Used for multi-level aggregation. ROLLUP gives subtotals; CUBE gives all combinations of subtotals. |
df.groupBy(“column1”).rollup(“column2”).agg(func.sum(“value”)) or df.groupBy(“column1”).cube(“column2”).agg(func.avg(“value”)) |
18 |
WINDOW Functions (OVER) |
Used for performing operations over a specific window (like running totals). |
df.withColumn(“running_total”, sum(“value”).over(Window.orderBy(“date”))) |
Conclusion
This table provides an easy-to-understand guide to SQL execution order and its corresponding PySpark syntax. Understanding this flow allows you to effectively transition from writing SQL queries to performing the same operations in PySpark.
The table offers a quick reference for handling common SQL operations such as joins, grouping, aggregation, sorting, and window functions, along with their direct equivalents in PySpark.
This should help beginners and experienced users alike improve their knowledge and productivity when working with large-scale data using Apache Spark.
Happy coding!